Access IPEDS data
1 Introduction
IPEDS “gathers information from every college, university, and technical and vocational institution that participates in the federal student financial aid programs” (as stated on their Web page). If you’re looking for cross-institution data on higher ed to use in your analyses, then this is the place to go.
cf https://github.com/UrbanInstitute/education-data-package-r
2 General landscape
The Urban Institute is a non-profit research organization which strives to be a trusted source for data related to economic and social policy research (their mission and values page). As part of this, they maintain their Center on Education Data and Policy which conducts research on and houses publically-available data about Pre-K through post-secondary education.
The U.S. federal government gathers and releases a large amount of data related to all of the above through several departments and initiatives. The Urban Institute maintains their Education Data Portal on which they currently provide data from twelve of those sources, one of which is IPEDS data. (You can see the surveys, their data, and the data dictionaries at this page.) As part of this, they provide an R package, educationdata, that enables interested parties to access the data from within R.
On this page, we provide an introduction to this package and then demonstrate how it might be used.
3 Finding data available
3.1 Package installation
As usual, when encountering a new package, you have to install it before you can use it. In this case, you might need to install educationdata:
After you execute the above (only once, before the first time you use it), you need to activate it for this usage:
4 Data exploration
4.1 Three primary arguments
The most basic call is this:
A note on these arguments:
level: This can take the following values, though we are going to focus onundergraduate.undergraduategraduatefirst-professionalpost-baccalaureate99(total of all)
source: The Urban Institute collects data from several sources (look under “Available Endpoints” on this page), but we focus onipedson this page.topic: IPEDS data covers many topics. The best place to scan what you might be interested in is this page. Some relevant ones—among many others—include the following:academic-year-room-board-otheracademic-year-tuitionadmissions-enrollmentcompletersenrollment-full-time-equivalent
Rows: 196,186
Columns: 9
$ unitid <int> 100636, 100636, 100636, 100654, 100654, 100654, …
$ year <int> 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, …
$ fips <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ number_applied <int> NA, NA, NA, 968, 1212, 2180, 1181, 1991, 3172, N…
$ number_admitted <int> NA, NA, NA, 799, 837, 1636, 1066, 1820, 2886, NA…
$ number_enrolled_ft <int> NA, NA, 0, 548, 576, 1124, 459, 765, 1224, NA, N…
$ number_enrolled_pt <int> NA, NA, 0, 9, 9, 18, 34, 43, 77, NA, NA, 0, 17, …
$ number_enrolled_total <int> 0, 0, 0, 557, 585, 1142, 493, 808, 1301, 0, 0, 0…
$ sex <int> 1, 2, 99, 1, 2, 99, 1, 2, 99, 1, 2, 99, 1, 2, 99…As you can see, this is a lot of data — 196186 rows! Let’s learn a bit about the columns. First, let’s see what values are in unitid:
# A tibble: 10,766 × 2
unitid `Number per unit`
<int> <int>
1 100636 6
2 100654 67
3 100663 67
4 100690 12
5 100706 67
6 100724 65
7 100733 6
8 100751 67
9 100760 6
10 100788 3
# ℹ 10,756 more rowsThe unitid is a unique identification number assigned to each institution. Over ten thousand institutions are represented in this data frame. You can use this page to look up an institution’s id.
Now let’s take a look at the values in the year column:
# A tibble: 22 × 2
year `Data per year`
<int> <int>
1 2001 29307
2 2002 20469
3 2003 8733
4 2004 8405
5 2005 8418
6 2006 8558
7 2007 8586
8 2008 8510
9 2009 8402
10 2010 7080
# ℹ 12 more rowsWe can see that 22 years are represented, from 2001 to 2022.
Next, let’s see what the fips column holds. FIPS codes are unique identifying values for states and territories.
fips Data per FIPS
1 1 2562
2 2 400
3 4 2226
4 5 1957
5 6 17163
6 8 2894
7 9 2518
8 10 469
9 11 704
10 12 7865
11 13 5163
12 15 707
13 16 760
14 17 7482
15 18 4683
16 19 3009
17 20 2272
18 21 2786
19 22 2834
20 23 1568
21 24 2740
22 25 6655
23 26 5128
24 27 3768
25 28 1464
26 29 5793
27 30 800
28 31 1612
29 32 910
30 33 1261
31 34 4618
32 35 940
33 36 17358
34 37 5182
35 38 661
36 39 8427
37 40 2673
38 41 2617
39 42 14319
40 44 921
41 45 3036
42 46 1015
43 47 4551
44 48 9165
45 49 1160
46 50 1236
47 51 4870
48 53 3026
49 54 2097
50 55 3514
51 56 163
52 60 6
53 64 79
54 66 79
55 68 45
56 69 6
57 70 6
58 72 4192
59 78 71This data frame holds 59 distinct values in this column.
Finally, we have the sex column. This information is currently not well-defined (as pertaining to either “sex” or “gender”, as they use these terms interchangeably), but mainly reflects male (1) and female (2). (I have not been able to find what 2, 3, and 99 mean.)
4.2 Two other arguments
The get_education_data() function has two more useful arguments that you should learn about — filters and add_labels.
4.2.1 filter
Just as you might guess, filters is a tool for choosing which rows you want to download. For college-university, ipeds, and admissions-enrollment, the only filter is year. Values for the filters argument must always be expressed as a list. For example, if we wanted to download the data for 2021, we would do the following:
enroll_2021 = get_education_data(level = 'college-university',
source = 'ipeds',
topic = 'admissions-enrollment',
filters = list(year = 2021))
glimpse(enroll_2021)Rows: 5,943
Columns: 9
$ unitid <int> 100654, 100654, 100654, 100663, 100663, 100663, …
$ year <int> 2021, 2021, 2021, 2021, 2021, 2021, 2021, 2021, …
$ fips <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ number_applied <int> 2209, 4345, 6560, 4139, 7767, 11906, 2850, 2931,…
$ number_admitted <int> 1599, 3092, 4697, 3501, 7040, 10541, 2301, 1958,…
$ number_enrolled_ft <int> 623, 834, 1459, 816, 1545, 2361, 772, 419, 1191,…
$ number_enrolled_pt <int> 24, 51, 75, 19, 35, 54, 6, 7, 13, 46, 47, 93, 15…
$ number_enrolled_total <int> 647, 885, 1534, 835, 1580, 2415, 778, 426, 1204,…
$ sex <int> 1, 2, 99, 1, 2, 99, 1, 2, 99, 1, 2, 99, 1, 2, 99…As you can see, this downloads 5943 rows.
Now, if we were to want to download data for 2018–2022, we would do the following:
enroll_201822 = get_education_data(level = 'college-university',
source = 'ipeds',
topic = 'admissions-enrollment',
filters = list(year = 2018:2022))
glimpse(enroll_201822)Rows: 32,746
Columns: 9
$ unitid <int> 100654, 100654, 100654, 100663, 100663, 100663, …
$ year <int> 2018, 2018, 2018, 2018, 2018, 2018, 2018, 2018, …
$ fips <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ number_applied <int> 3210, 6428, 9638, 2745, 5100, 7845, 2557, 1986, …
$ number_admitted <int> 2793, 5868, 8661, 2532, 4694, 7226, 2133, 1541, …
$ number_enrolled_ft <int> 624, 901, 1525, 803, 1442, 2245, 905, 523, 1428,…
$ number_enrolled_pt <int> 1, 3, 4, 23, 31, 54, 3, 4, 7, 8, 5, 13, 14, 17, …
$ number_enrolled_total <int> 625, 904, 1529, 826, 1473, 2299, 908, 527, 1435,…
$ sex <int> 1, 2, 99, 1, 2, 99, 1, 2, 99, 1, 2, 99, 1, 2, 99…This gets us a lot more data—a total of 32746 rows.
4.2.2 add_labels
Note that we still do not know what the values in the sex column mean. It turns out that we can fix that with the add_labels argument.
Simply set add_labels = TRUE and it will define appropriate columns as factors so that the analyst can more easily work with the data. Consider this:
enroll_2022 = get_education_data(level = 'college-university',
source = 'ipeds',
topic = 'admissions-enrollment',
filters = list(year = 2022),
add_labels = TRUE)
glimpse(enroll_2022)Rows: 8,686
Columns: 9
$ unitid <int> 100654, 100654, 100654, 100654, 100663, 100663, …
$ year <int> 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, …
$ fips <fct> Alabama, Alabama, Alabama, Alabama, Alabama, Ala…
$ number_applied <int> 2924, 5983, 0, 8907, 3451, 6496, 0, 9947, 2822, …
$ number_admitted <int> 1932, 4160, 0, 6092, 2870, 5752, 0, 8622, 2320, …
$ number_enrolled_ft <int> 675, 1009, 0, 1684, 733, 1439, 0, 2172, 743, 411…
$ number_enrolled_pt <int> 14, 26, 0, 40, 22, 23, 0, 45, 10, 8, 0, 18, 1, 4…
$ number_enrolled_total <int> 689, 1035, 0, 1724, 755, 1462, 0, 2217, 753, 419…
$ sex <fct> Male, Female, Unknown, Total, Male, Female, Unkn…We can use the following to see which values of sex were used in the 2022 data:
get_education_data(level = 'college-university',
source = 'ipeds',
topic = 'admissions-enrollment',
filters = list(year = 2022),
add_labels = TRUE) |>
group_by(sex) |>
summarize("# of pieces of data" = n())# A tibble: 5 × 2
sex `# of pieces of data`
<fct> <int>
1 "Male" 1991
2 "Female" 1991
3 "Gender " 722
4 "Unknown" 1991
5 "Total" 1991It appears that each institution submitted each piece of data.
5 The process
Before we proceed, let’s note what data we’re looking for. We are going to be running our initial investigation into how undergraduate enrollment has changed. Much more will have to be done after this but the following will get us familiar with some of the data that we can get from IPEDS.
5.1 Overview
Before downloading the data that you need, you will want to
- Determine the data set that you want to access.
- Determine which filters you want to set in your download query.
Only then can you download the data.
After downloading that data and storing it as a data frame, you can then proceed as follows:
- Explore the data to ensure that you understand what’s in each column, what each row represents, and what data is missing. In other words, validate the data.
- Construct exploratory data analysis on the data frame (with queries, graphs, and statistical analysis) to see if you can answer the questions that you want to answer.
- Refine queries, graphs, and analysis appropriately given their importance and visibility.
5.2 Download and prepare the data
First, we shall get the most recent available data on the admit funnel.
From this page, we see that we can filter by year when querying admissions-enrollment.
max_year = df |> distinct(year) |> max()
enroll_max_year = get_education_data(level = 'college-university',
source = 'ipeds',
topic = 'admissions-enrollment',
filters = list(year = max_year),
add_labels = TRUE)
glimpse(enroll_max_year)Rows: 8,686
Columns: 9
$ unitid <int> 100654, 100654, 100654, 100654, 100663, 100663, …
$ year <int> 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, …
$ fips <fct> Alabama, Alabama, Alabama, Alabama, Alabama, Ala…
$ number_applied <int> 2924, 5983, 0, 8907, 3451, 6496, 0, 9947, 2822, …
$ number_admitted <int> 1932, 4160, 0, 6092, 2870, 5752, 0, 8622, 2320, …
$ number_enrolled_ft <int> 675, 1009, 0, 1684, 733, 1439, 0, 2172, 743, 411…
$ number_enrolled_pt <int> 14, 26, 0, 40, 22, 23, 0, 45, 10, 8, 0, 18, 1, 4…
$ number_enrolled_total <int> 689, 1035, 0, 1724, 755, 1462, 0, 2217, 753, 419…
$ sex <fct> Male, Female, Unknown, Total, Male, Female, Unkn…The above first sets the value of max_year to 2022 (from our previous download of the data). Note the following:
For the rest of this page, we never specify an actual year in our queries — it is always computed from the data! This is a bit more work now, but in future years if we were to repeat this analysis, we would not have to update our queries. This is a good habit to get into: if you find yourself putting a fixed string or integer value in a series of queries, you should at least create a variable to hold the value at the top of all of your work so that the values can be easily found and updated at a later time. A better approach, though one that is not always available, is to calculate the value so that it can update itself.
Now we get the oldest values for comparison. We again start by computing the year—this time, the minimum year—from the data.
min_year = df |> distinct(year) |> min()
enroll_min_year = get_education_data(level = 'college-university',
source = 'ipeds',
topic = 'admissions-enrollment',
filters = list(year = min_year),
add_labels = TRUE)
glimpse(enroll_min_year)Rows: 29,307
Columns: 9
$ unitid <int> 100636, 100636, 100636, 100654, 100654, 100654, …
$ year <int> 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, …
$ fips <fct> Alabama, Alabama, Alabama, Alabama, Alabama, Ala…
$ number_applied <int> NA, NA, NA, 968, 1212, 2180, 1181, 1991, 3172, N…
$ number_admitted <int> NA, NA, NA, 799, 837, 1636, 1066, 1820, 2886, NA…
$ number_enrolled_ft <int> NA, NA, 0, 548, 576, 1124, 459, 765, 1224, NA, N…
$ number_enrolled_pt <int> NA, NA, 0, 9, 9, 18, 34, 43, 77, NA, NA, 0, 17, …
$ number_enrolled_total <int> 0, 0, 0, 557, 585, 1142, 493, 808, 1301, 0, 0, 0…
$ sex <fct> Male, Female, Total, Male, Female, Total, Male, …In order to facilitate our coming analysis, we need to combine these two data frames into one with the bind_rows() command:
If you are going to run these statements in an R script, then you should execute the following in order to clean up the environment:
If you are going to execute all of this within a Quarto document, then this step is unnecessary.
5.3 A decision
An alternative approach to gathering your data is available. Once you understand know what level, source, and topic values you are going to submit (and have already decided to set add_labels to TRUE), then you — as a user of R — have a decision to make:
Should you use the tidyverse’s
filter()capabilities after downloading all of the data, or should you use thefiltercapabilities withinget_education_data()as a base-level filter in order to minimize the amount of data that you actually download. You might choose the second if your download speeds are slow or download costs are high. However, as a skilled user of the tidyverse, it probably makes sense to skip thefiltercapabilities ofget_education_data()altogether as they are just another tool that you have to learn how to use.
If you decide to use the tidyverse’s filter() capabilities, then you could accomplish the above using the following code.
enroll = get_education_data(level = 'college-university',
source = 'ipeds',
topic = 'admissions-enrollment',
add_labels = TRUE)
max_year = enroll |> distinct(year) |> max()
min_year = enroll |> distinct(year) |> min()
enroll =
enroll |>
filter(year %in% c(min_year, max_year))
enroll |>
arrange(unitid, year) |>
head(10) unitid year fips number_applied number_admitted number_enrolled_ft
1 100636 2001 Alabama NA NA NA
2 100636 2001 Alabama NA NA NA
3 100636 2001 Alabama NA NA 0
4 100654 2001 Alabama 968 799 548
5 100654 2001 Alabama 1212 837 576
6 100654 2001 Alabama 2180 1636 1124
7 100654 2022 Alabama 2924 1932 675
8 100654 2022 Alabama 5983 4160 1009
9 100654 2022 Alabama 0 0 0
10 100654 2022 Alabama 8907 6092 1684
number_enrolled_pt number_enrolled_total sex
1 NA 0 Male
2 NA 0 Female
3 0 0 Total
4 9 557 Male
5 9 585 Female
6 18 1142 Total
7 14 689 Male
8 26 1035 Female
9 0 0 Unknown
10 40 1724 TotalIn this case, this enroll data frame has 37993 rows.
5.4 Validation
Now that we have the data downloaded into R, we should go through some basic validation.
First, let’s simply look at what we have:
unitid year fips number_applied number_admitted number_enrolled_ft
1 100636 2001 Alabama NA NA NA
2 100636 2001 Alabama NA NA NA
3 100636 2001 Alabama NA NA 0
4 100654 2001 Alabama 968 799 548
number_enrolled_pt number_enrolled_total sex
1 NA 0 Male
2 NA 0 Female
3 0 0 Total
4 9 557 MaleLong column names can make it harder to read a data frame. Let’s rename the columns to shorten them:
And now let’s take another look:
unitid year fips NumApply NumAdmit NumEnrFT NumEnrPT NumEnrTot sex
1 100636 2001 Alabama NA NA NA NA 0 Male
2 100636 2001 Alabama NA NA NA NA 0 Female
3 100636 2001 Alabama NA NA 0 0 0 Total
4 100654 2001 Alabama 968 799 548 9 557 Male
5 100654 2001 Alabama 1212 837 576 9 585 Female
6 100654 2001 Alabama 2180 1636 1124 18 1142 Total
7 100663 2001 Alabama 1181 1066 459 34 493 Male
8 100663 2001 Alabama 1991 1820 765 43 808 Female
9 100663 2001 Alabama 3172 2886 1224 77 1301 Total
10 100690 2001 Alabama NA NA NA NA 0 MaleLet’s do some basic investigation to see if we can see how many institutions submitted each year:
It seems that there’s a lot more data for 2001.
As a reminder, the previous command is equivalent to the following:
# A tibble: 2 × 2
year `# of institutions`
<int> <int>
1 2001 29307
2 2022 8686Now let’s take a look at changes in number of students between the two years. The total number of students enrolling at an institution in a particular year is in the NumEnrFT column when sex == "Total". The following calculates the appropriate value.
diffs_temp = enroll |>
filter(sex == "Total") |>
group_by(fips, year) |>
summarize(TotFTByFIPSByYear = sum(NumEnrFT))
head(diffs_temp)# A tibble: 6 × 3
# Groups: fips [4]
fips year TotFTByFIPSByYear
<fct> <int> <int>
1 Alabama 2001 19443
2 Alabama 2022 29893
3 Alaska 2001 1811
4 Alaska 2022 840
5 American Samoa 2001 0
6 Arizona 2001 20520Now that we have the totals calculated, the most convenient way to calculate the difference between the two is to put the values for a particular FIPS code on one row. This is handled by the pivot_wider() function. As you can see by the resulting table, the columns will be fips, yr2001, and yr2022.
diffs_spread = diffs_temp |>
pivot_wider(names_from = year,
names_prefix = "yr",
values_from = TotFTByFIPSByYear)
head(diffs_spread)# A tibble: 6 × 3
# Groups: fips [6]
fips yr2001 yr2022
<fct> <int> <int>
1 Alabama 19443 29893
2 Alaska 1811 840
3 American Samoa 0 NA
4 Arizona 20520 NA
5 Arkansas 13903 16598
6 California 117031 NABy the way, I use the names_prefix argument because having integer values as column names can be tricky to handle. Appending a prefix at the beginning of the integer changes it to a string.
We could calculate the difference between the two columns with the following code:
However, this violates our desire to not “hard code” the years into our calculations. We could do this…but let’s try not to! Consider the following code that does this for us:
max_yr = paste0("yr", max_year)
min_yr = paste0("yr", min_year)
diffs = diffs_spread |>
mutate(difference = !!sym(max_yr) - !!sym(min_yr)) |>
arrange(desc(difference))
head(diffs)# A tibble: 6 × 4
# Groups: fips [6]
fips yr2001 yr2022 difference
<fct> <int> <int> <int>
1 Georgia 40730 57881 17151
2 Ohio 46552 60357 13805
3 Alabama 19443 29893 10450
4 South Carolina 19278 28893 9615
5 New Jersey 26297 34785 8488
6 Maryland 18619 24130 5511(The differences seem large, and should be spot checked from another source. We might also need to increase percentage changes between the years.)
The first steps accomplish setting max_yr to “yr2022” and min_yr to “yr2001”. The paste0() function takes two values and concatenates them together to create a string without a space in between.
We are now going to take a detailed look at line 5 from the above code:
- The combination of the
sym()and!!(pronounced as “bang bang”) functions converts a string into an R symbol that is usable as a column reference. - The
differencecalculation effectively subtracts the yr2001 column from the yr2022 column.
Again, this somewhat messy and complicated approach ensures that your string representations of column names are correctly interpreted as column references within mutate().
Next, let’s see how many of these rows have blank values:
# A tibble: 24 × 4
# Groups: fips [24]
fips yr2001 yr2022 difference
<fct> <int> <int> <int>
1 American Samoa 0 NA NA
2 Arizona 20520 NA NA
3 California 117031 NA NA
4 Colorado 24296 NA NA
5 District of Columbia 7978 NA NA
6 Florida 53913 NA NA
7 Illinois 46624 NA NA
8 Indiana 41361 NA NA
9 Iowa 19361 NA NA
10 Massachusetts 44782 NA NA
# ℹ 14 more rowsIt looks like 24 states have no data in some column. For now, let’s restrict to the states that have data for both years. First, let’s create a vector of fips codes for which R was able to calculate difference:
keep = diffs |>
filter(!is.na(difference)) |>
pull(fips) # convert the column to a vector, no longer a data frame
glimpse(keep) Factor w/ 79 levels "Alabama","Alaska",..: 13 39 1 45 34 24 49 53 16 21 ...As a final step, let’s filter() only those rows for which the fips code is one of the codes in keep:
unitid year fips NumApply NumAdmit NumEnrFT NumEnrPT NumEnrTot sex
1 100636 2001 Alabama NA NA NA NA 0 Male
2 100636 2001 Alabama NA NA NA NA 0 Female
3 100636 2001 Alabama NA NA 0 0 0 Total
4 100654 2001 Alabama 968 799 548 9 557 Male
5 100654 2001 Alabama 1212 837 576 9 585 Female
6 100654 2001 Alabama 2180 1636 1124 18 1142 Total5.5 Visualization
Let’s make a plot of the percentage differences for full-time students:
enroll |>
filter(sex == "Total") |>
group_by(year, fips) |>
summarize(total = sum(NumEnrFT)) |>
pivot_wider(names_from = year,
values_from = total) |>
# filter out small ones
filter(!!sym(as.character(min_year)) > 1000) |>
mutate(change = (!!sym(as.character(max_year)) -
!!sym(as.character(min_year))) /
!!sym(as.character(min_year))) |>
# now plot it
ggplot(aes(x = change,
y = reorder(fips,change),
fill = change)) +
geom_col(color = "black") +
theme_bw() +
labs(title = "% change in FT Enrollments",
subtitle = paste("From", min_year, "to", max_year),
x = "% change",
y = element_blank(),
fill = element_blank()) +
scale_fill_distiller(palette = "RdBu",
direction = 1,
name = "% Change",
limits = c(-0.75, 0.75),
breaks = c(-0.75, -0.5, -0.25, 0, 0.25, 0.5, 0.75),
labels = c("-75%", "-50%", "-25%", "None",
"25%", "50%", "75%")) +
scale_x_continuous(limits = c(-0.75, 0.75),
breaks = c(-0.75, -0.5, -0.25, 0, 0.25, 0.5, 0.75),
labels = c("-75%", "-50%", "-25%", "None",
"25%", "50%", "75%"))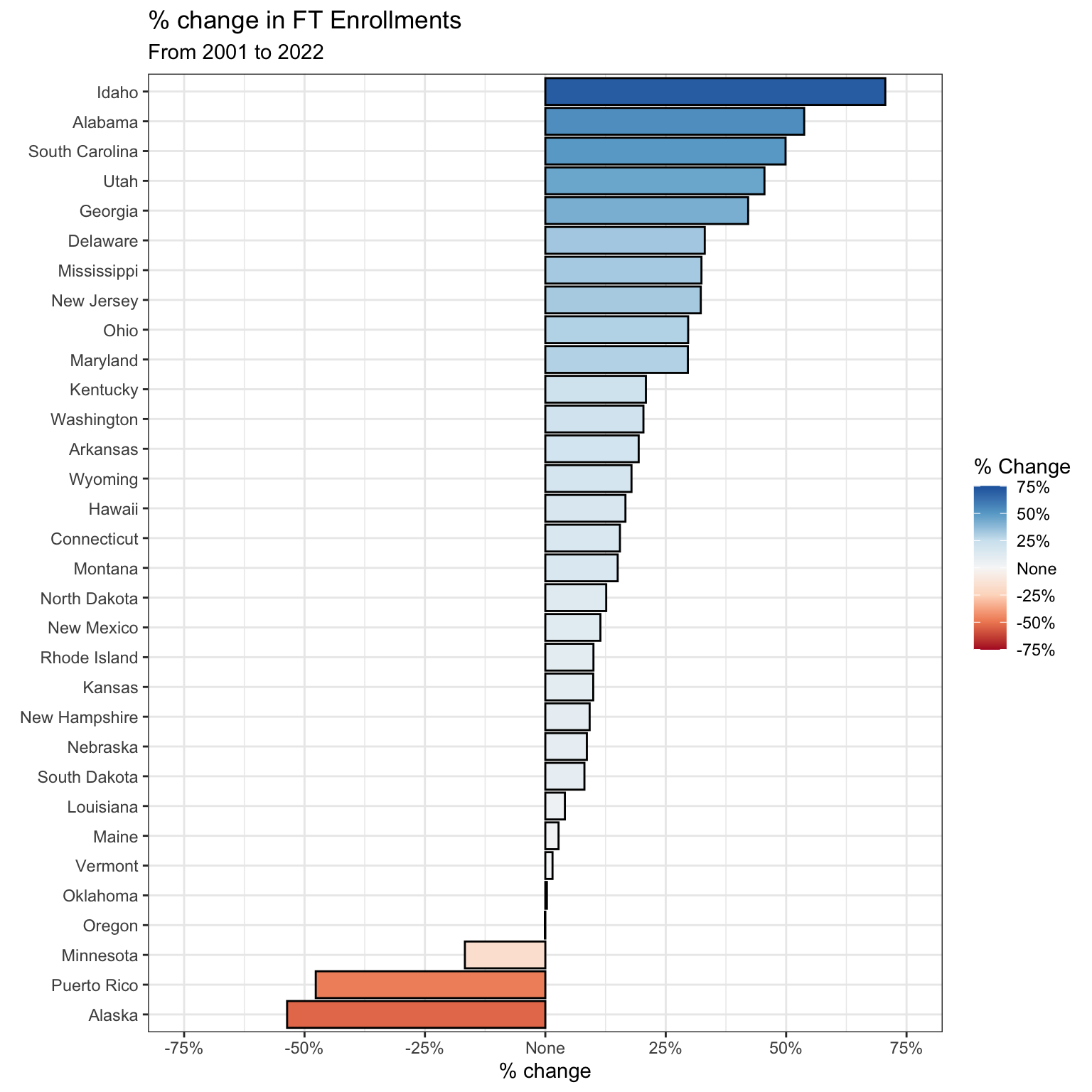
You might notice the !!sym(as.character(min_year) in the above. In this query we kept the column number for the year data as integers. This is how you handle converting from a variable with an integer value to a column of that name.